近日,哈工大深圳校区马婷教授课题组在三维神经影像多任务学习领域取得重要进展,创新性地提出了首个适用于三维神经影像的通用“上下文学习”(In-Context Learning, ICL)模型——Neuroverse3D。该模型能够在无需重新训练的前提下,完成包括脑组织分割、去噪、图像修复等多种神经影像任务,为实现精准、高效、可泛化的脑影像智能分析提供了新范式。相关成果以《Neuroverse3D: Developing In-Context Learning Universal Model for Neuroimaging in 3D》为题,发表在计算机视觉顶会《国际计算机视觉大会》(IEEE International Conference on Computer Vision 2025)。
神经影像分析是现代神经科学和临床脑疾病诊疗中的关键工具。近年来,通用模型凭借其对多模态、多任务的广泛适应性,成为人工智能医疗领域的重要研究方向。其中,上下文学习(ICL)方法因其在不改变模型参数的情况下即可完成新任务的能力而备受关注。然而,已有ICL模型大多基于2D图像切片输入,无法保留神经影像中的三维结构信息,限制了其在医学影像、特别是脑部三维结构分析中的实际应用。
针对上述问题,课题组提出了Neuroverse3D模型,首次实现了3D神经影像场景下的通用ICL能力。该模型采用自适应并行-顺序处理机制(Adaptive Parallel-Sequential Processing, APSP),结合U型上下文融合策略,有效解决了3D图像在ICL场景下面临的内存瓶颈问题,可灵活支持任意数量的上下文图像输入,显著提升了模型的可扩展性与实用性。同时,团队还设计了一种多任务优化损失函数,强化了模型对解剖结构边界的识别能力,显著提升了模型在高难度分割任务中的表现。
在43,000余个来自19个公开数据集的多模态神经影像训练基础上,Neuroverse3D在14项具有代表性的任务上进行了广泛评估。结果显示,该模型在无需针对特定任务进行调优的情况下,依然取得了优于现有ICL方法的性能,甚至在多个任务上接近甚至超越了任务专用模型的表现,平均在部分关键任务上获得超过20个Dice分数点的提升。
本研究为多中心、多病种、多模态的神经影像分析提供了一种高度可迁移、无需重新训练的统一解决方案,为脑疾病的智能辅助诊断、治疗响应监测以及多源影像协同分析奠定了坚实基础。未来,该方法有望广泛应用于临床AI系统构建与脑影像大模型的发展中,助力构建更加开放、高效、智能的医学影像分析生态体系。
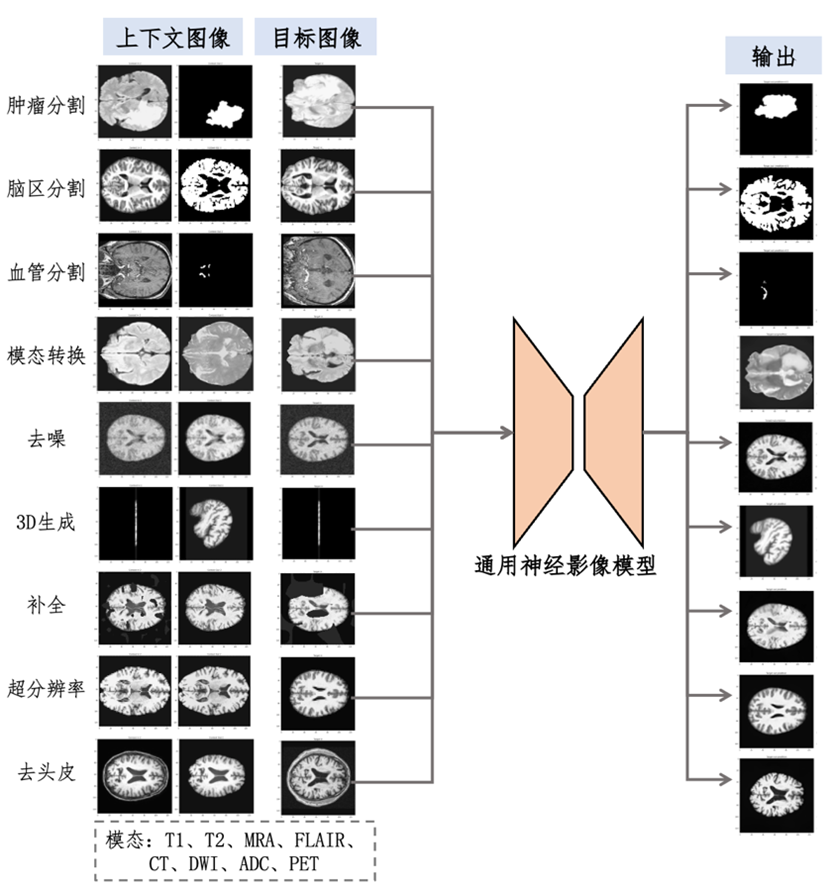
图1. 展示了神经影像通用模型所覆盖的多种任务类型,包括图像分割、图像增强和图像生成等。该模型采用“一模型多任务”的范式,不仅具备强大的跨中心、跨任务和跨模态的泛化能力,还能够在无需微调的情况下应对从未见过的新任务。
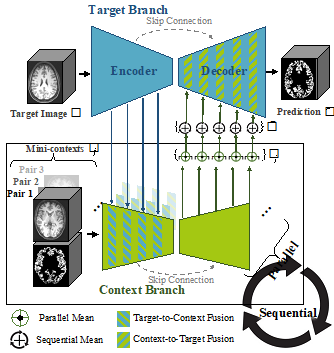
图2. 我们模型架构的示意图如图所示。该网络由两个分支组成,分别用于提取目标图像和上下文图像的特征表示。目标到上下文融合模块与上下文到目标融合模块实现了两个分支之间的信息交互。我们的模型能够自适应地执行并行与顺序的上下文处理操作。

 综合新闻
综合新闻 科研动态
科研动态
