自监督学习(SSL)作为一种新兴的人工智能学习范式,在处理大规模、未标记的神经影像数据方面展现出巨大潜力,为脑疾病的自动化分析和理解提供了新的途径。典型的基于SSL的脑疾病分析流程通常包含两个核心阶段:首先,上游的脑网络构建阶段涉及从个体采集的原始神经影像数据(如fMRI、EEG等)出发,经过数据预处理,生成结构化的大脑表征,例如功能/结构连接矩阵或时间序列特征。随后,这些大脑表征被输入到下游的自监督学习模型中,该模型通常采用编码器-解码器架构,编码器将输入数据映射到低维的潜空间。通过精心设计的代理任务和相应的损失函数,模型从未标记数据中学习有意义的特征表示。这些学习到的鲁棒特征最终被用于各种下游任务,包括疾病检测、疾病预测以及其他相关的临床应用,从而促进对脑功能障碍机制的深入理解和临床决策支持。
Science合作期刊《Health Data Science》近期发表了哈尔滨工业大学(深圳)医工学院叶辰飞/马婷团队的综述论文:Self-supervised learning to unveil brain dysfunctional signatures in brain disorders: Methods and applications。该论文系统综述了自监督学习(SSL)技术在神经影像数据分析中的应用,特别关注其在解析各类神经精神疾病中脑功能障碍特征的潜力。研究团队系统梳理了近年来SSL在神经退行性疾病、精神障碍及其他神经系统疾病中的成功应用案例,展示了其在识别疾病特异性生物标志物、理解疾病进展的脑网络动态变化等方面的潜力。例如,在阿尔茨海默病研究中,SSL模型能够捕捉到脑功能网络的早期轻微病变;在孤独症谱系障碍研究中,则有助于揭示复杂的连接模式异常。
在神经影像领域,数据标注成本高昂,而未标记数据却十分丰富。“代理任务”(Pretext Tasks)的引入使我们能够充分利用这些未标记的神经影像数据来预训练模型,并学习脑网络或脑活动模式的通用表征。这些表征可以有效地迁移到各种下游任务,例如脑疾病分类和疾病严重程度回归,从而提高模型在这些任务上的性能,并增强模型在不同数据集上的泛化能力。在神经影像领域,“代理任务”的设计还需要充分考虑神经影像数据的特性,例如高维度、时空依赖性和图结构。本论文重点介绍了几种典型的自监督学习(SSL)技术,包括对比学习、生成学习以及生成-对比学习,如图1所示。
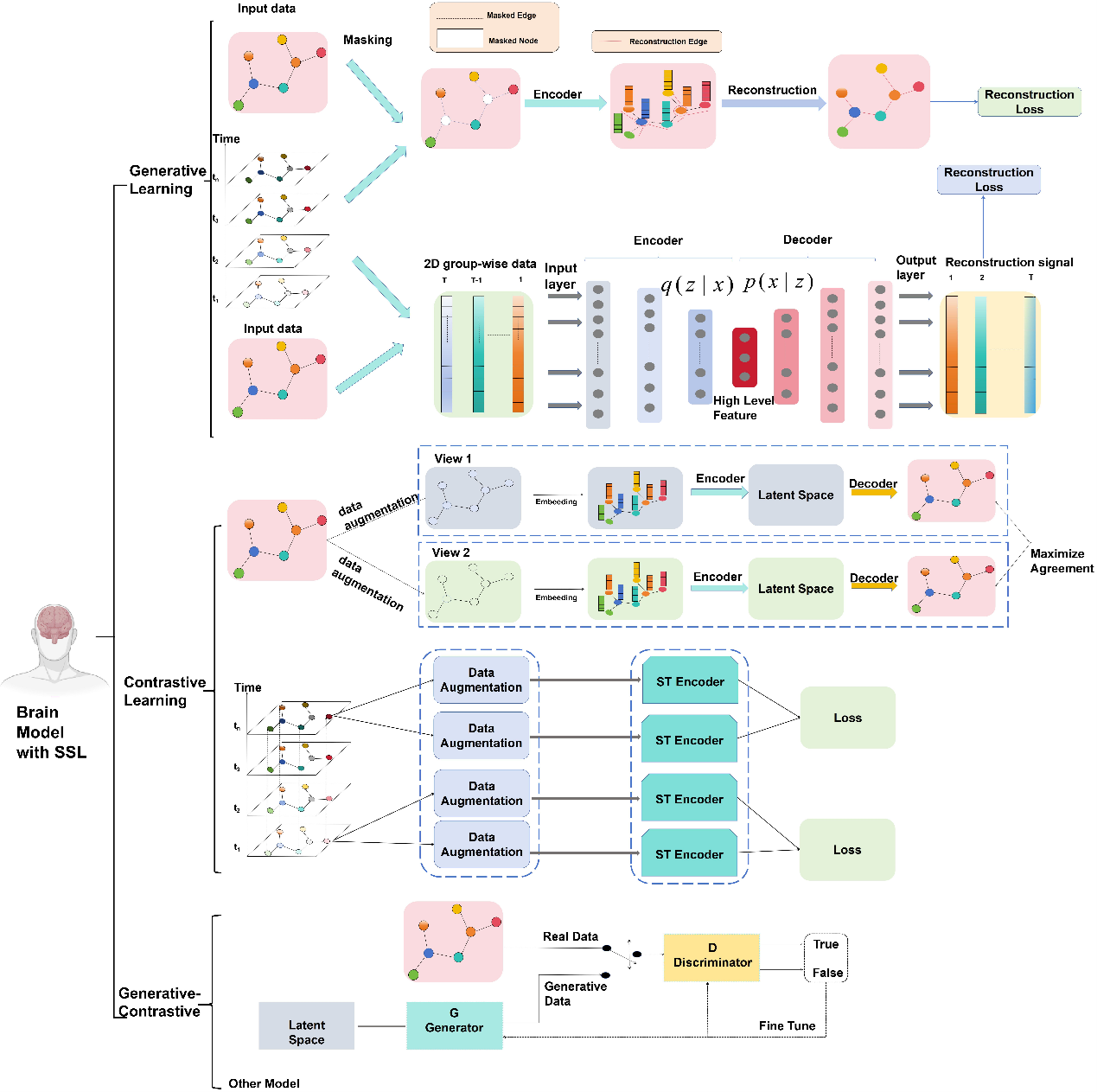
图1 在基于神经影像的医学应用中,自监督学习(SSL)模型内的主要学习策略
自监督学习(SSL)在脑部疾病领域的应用,首要优势在于解决精神障碍中普遍存在的跨诊断异质性问题。它利用大量未标记的脑功能数据,通过捕捉大脑功能的动态重构模式,在识别跨诊断精神病理的新亚型方面展现出巨大潜力。这不仅为深入解析精神障碍的病理生理机制提供了新证据,也为制定更精准的个体化治疗方案奠定了基础。
此外,SSL模型在脑活动解码方面有望阐明认知状态背后的功能性大脑机制。神经科学最新研究表明,从视频刺激触发的 fMRI 信号中可以高保真地重建视觉语义信息。因此,将基于 SSL 的模型整合进神经精神疾病患者任务态脑功能记录的解码过程,也将有助于解析脑功能障碍的潜在机制。这类模型为连接神经科学与临床实践提供了有前景的途径,并最终支持创新治疗策略的开发。
未来的研究重点应包括设计适用于医学场景的特定预训练任务,例如将患者访谈视频片段与电子病历中的对应诊断描述进行对齐,并构建未标记的医学多模态数据集进行验证。这种拓展不仅能增强 SSL 在医疗保健领域的应用广度,还能有效利用多模态医疗数据固有的监督信号,减少对昂贵标注的依赖。
哈工大深圳校区为论文第一完成单位。哈工大深圳信息学院硕士生李莹、德国图宾根心理健康中心博士后杨延武为论文共同第一作者。医工学院马婷、叶辰飞为论文共同通讯作者。该研究工作获得了国家自然科学基金面上项目和深圳市科技创新项目的支持。
Li Y, Yang Y, Chen Y, Ye C, Ma T. Self-Supervised Learning to Unveil Brain Dysfunctional Signatures in Brain Disorders: Methods and Applications. Health Data Sci. 2025 Aug 5;5:0282. doi: 10.34133/hds.0282.

 综合新闻
综合新闻 科研动态
科研动态
